
お客様の課題
- 各 SaaS サービス(Salesforce、kintone、楽楽販売)に散在する顧客データの手動名寄せが属人化しており、統合の大きな妨げとなっていた。
- 企業情報の入力ルールがサービス間で統一されておらず、表記揺れやデータ欠損が発生し、データ精度に限界があった。
- ビジネス戦略策定などの意思決定に必要なデータとして精度を高める必要があった。

対応と結果
- 複数の SaaS サービスで共通して使える企業識別キーを自動で発行・配布する仕組みを構築し、分散していた顧客情報の一元管理を実現。
- 夜間に自動実行されるバッチ処理により、法人番号の取得や企業情報の更新を自動化し、手作業での名寄せ作業を不要に。
- 国税庁 API や帝国データバンクなどの外部データと独自の照合ロジックを組み合わせ、表記揺れに対応した高精度な名寄せを実装。
- データの一元化により、各 SaaS サービス間での情報の一貫性と信頼性が向上し、常に最新かつ正確な企業情報が自動的に反映される運用を実現。
スパイダープラス株式会社様では、営業部門やカスタマーサポート部門など複数部署で扱う顧客情報が各 SaaS サービスに分散して管理されていました。データ連携は会社名を軸とした手動の名寄せに依存していたため、担当者ごとの入力ルールによる表記揺れも発生。データ精度の向上が業務上の課題となっていました。
本プロジェクトにてアイレットは、Google Cloud を活用したデータ基盤を構築。複数の SaaS サービスを横断する共通キーの自動採番と、外部 API を活用した高精度な名寄せの仕組みを実現しました。
複数 SaaS サービスに分散する顧客データ。一元管理に向けたデータ基盤を構築
建設 DX サービス「SPIDER+」の開発・販売を手がけるスパイダープラス株式会社様(以下、スパイダープラス様)では、Salesforce や kintone、楽楽販売など、部署や用途に応じて複数の SaaS サービスを運用していました。しかし、企業情報の入力ルールがサービス間で統一されておらず、記入内容が各個人によって異なるため、顧客データが分散。
例えば、「株式会社」と「(株)」のように表記揺れが発生し、同一企業であっても各サービスで異なる表記が登録されるケースが散見され、社内担当者が手動で名寄せを行なう手間が発生していました。こうしたデータ品質の課題により、営業フローの可視化や経営戦略の意思決定に必要なデータを確保することが困難な状況でした。
そこで、将来的に全データを集約した分析基盤の構築を見据え、第一歩として、複数の SaaS ツールを横断して企業を一意に管理できる共通キーの採番と、データの一元管理を実現する基盤の構築が求められました。
Cloud SQL で企業マスタを構築。共通キーの自動採番と外部 API による高精度な名寄せを実現
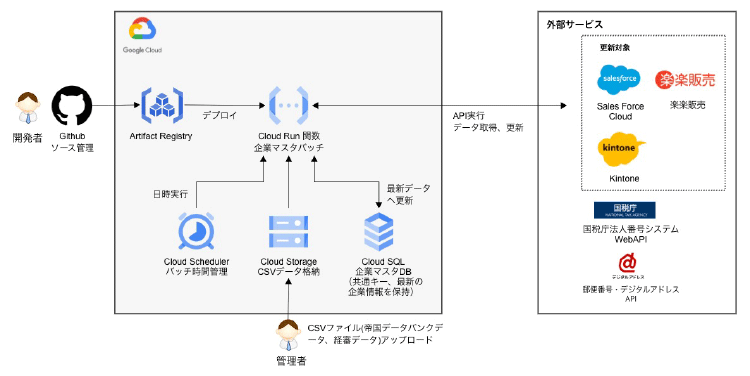
本プロジェクトでは、Google Cloud の Cloud SQL を用いて企業マスタを構築し、複数の SaaS サービスを横断して企業を一意に特定できる共通キーを自動採番・配布する仕組みを実装。この企業マスタが各 SaaS の企業情報を統合管理する中核となり、共通キーと最新の企業データを保持する役割を果たしています。
データ処理には Cloud Run Functions を活用したサーバーレス基盤を採用し、各 SaaS からのデータ収集、同期、反映を自動化。Cloud Scheduler による夜間バッチ処理により、各サービス上の顧客情報を毎日最新の状態へ自動的にアップデートする運用が可能となりました。
例えば、一つのツールで情報が変更された場合、その内容が他のツールにも反映されるなど、双方向でのデータ同期を実現しています。これにより、入力時に省略形などで登録された場合でも、夜間バッチ処理により正式な表記に自動統一され、各 SaaS サービス上のデータ品質が維持されるようになりました。
名寄せの精度向上には、国税庁 API や郵便局 API、帝国データバンクといった複数の外部データソースを優先度に応じて統合しました。帝国データバンクのデータを正規データとして基準に設定し、社名や住所の表記揺れがある場合でも、独自の照合ロジックにより正確な法人番号を特定。一貫性のある共通キーを採番する仕組みを構築しています。
法人番号を持たないデータについては、会社名・住所・郵便番号などの情報から該当企業を検索。複数の項目が一致した場合には該当企業として共通キーを付与し、一致しないものはエラーとして出力することで、スパイダープラス様側で判断いただく運用としました。このアプローチにより、自動処理の効率性と人的判断の正確性を両立させています。
外部 API の利用時には、レートリミットに抵触しないよう処理の待機時間やリクエスト回数を細かく調整しました。特に国税庁 API は公共サービスであるため利用制限が厳しく、大量のデータ処理を行なう際には段階的にリクエストを分散させる必要がありました。
また、CSV データには表記揺れやデータ欠損が多数存在していたため、これらを網羅的にサニタイズして Cloud SQL へ正しく反映させるロジックを実装。正規表現やマッチングルールを細かく設定し、データの正規化処理を行なっています。
本プロジェクトにより、各 SaaS サービス上の企業情報に共通キーが配布され、データの一元化と正確性が向上しました。法人番号の取得や企業情報のアップデートが自動化されたことで、手入力や手動での名寄せ作業が不要となり、常に最新かつ正確な情報が各サービスに反映される環境を実現。部署間でのデータの不統一も解消され、組織全体でのデータ活用がスムーズになりました。
複数の SaaS に分散していた顧客データを共通キーで紐付け。営業プロセスの可視化や顧客分析、経営判断に活用可能なデータ基盤を実現。
これまで業界内の企業リストが複数のデータソースに分散していた状態から一元管理へと移行したことで、顧客開拓におけるファネルごとの状況を可視化できるようになりました。従来は限定的なデータをもとに判定していた新規開拓リストも、統合データを活用することで抽出件数が大幅に向上し、営業活動の質と量の双方の改善に貢献しています。
今後は、名寄せ処理の自動化によってデータ分析にかかる工数削減と精度向上がさらに進むことが期待されます。また、顧客を一意に特定できる基盤が整備されたことで、集計や分析に用いるデータの粒度を統一することが可能となりました。データを最小単位で管理することで、どの単位で集計しても一貫した結果を得られる環境が整い、社内における数字の共通言語の確立にもつながります。さらに、正確な企業情報を参照できることに加え、それらが一元管理されたことで他データとの結合が容易になり、分析の幅が拡大。事業成長に向けた意思決定における指標の精度向上にも寄与していくことが期待されています。
アイレットでは、Google Cloud をはじめとするクラウド技術を活用したデータ基盤構築の豊富な支援実績から、お客様の業務に応じた柔軟なソリューション提供が可能です。データの一元化や自動化による業務効率化をご検討の企業様は、ぜひお気軽にご相談ください。
(使用プロダクト)
- ・Google Cloud
- Artifact Registry
- Cloud Run
- Cloud Scheduler
- Cloud Storage
- Cloud SQL
Credit
クライアントスパイダープラス株式会社

